前言
上下文这个概念多见于文章中,是一句话中的语境,也就是语言环境。一句莫名其妙的话出现会让人不理解什么意思,如果有语言环境的说明,则会更好,这就是语境对语意的影响。
上下文是一种属性的有序序列,为驻留在环境内的对象定义环境。在对象的激活过程中创建上下文,对象被配置为要求某些自动服务,如同步、事务、实时激活、安全性等等。
如在计算机中,相对于进程而言,上下文就是进程执行时的环境。具体来说就是各个变量和数据,包括所有的寄存器变量、进程打开的文件、内存信息等。可以理解上下文是环境的一个快照,是一个用来保存状态的对象。在程序中我们所写的函数大都不是单独完整的,在使用一个函数完成自身功能的时候,很可能需要同其他的部分进行交互,需要其他外部环境变量的支持,上下文就是给外部环境的变量赋值,使函数能正确运行。
请求上下文
关于WSGI
WSGI(全称Web Server Gateway Interface),是为 Python 语言定义的Web服务器和Web应用程序之间的一种简单而通用的接口,它封装了接受HTTP请求、解析HTTP请求、发送HTTP,响应等等的这些底层的代码和操作,使开发者可以高效的编写Web应用。
Flask提供了两种上下文,一种是应用上下文(Application Context),一种是请求上下文(Request Context)。
- RequestContext 请求上下文
- Request 请求的对象,封装了Http请求(environ)的内容
- Session 根据请求中的cookie,重新载入该访问者相关的会话信息。
- AppContext 程序上下文
- g 处理请求时用作临时存储的对象。每次请求都会重设这个变量
- current_app 当前激活程序的程序实例
参见Flask上下文官方文档 请求上下文 和 应用上下文.
- application 指的就是当你调用app = Flask(name)创建的这个对象app;
- request 指的是每次http请求发生时,WSGI server(比如gunicorn)调Flask.call()之后,在Flask对象内部创建的Request对象;
- application 表示用于响应WSGI请求的应用本身,request 表示每次http请求;
- application的生命周期大于request,一个application存活期间,可能发生多次http请求,所以,也就会有多个request
生命周期
current_app的生命周期最长,只要当前程序实例还在运行,都不会失效。
Request和g的生命周期为一次请求期间,当请求处理完成后,生命周期也就完结了
Session就是传统意义上的session了。只要它还未失效(用户未关闭浏览器、没有超过设定的失效时间),那么不同的请求会共用同样的session。
Flask处理流程
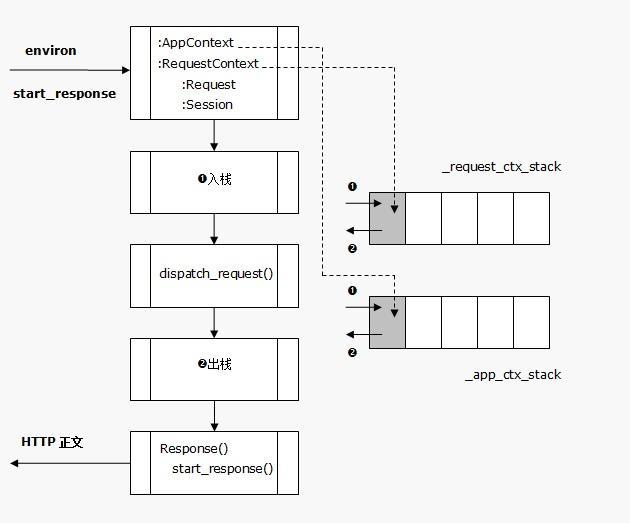
local线程隔离对象
不用local对象的情况
from threading import Thread
request = '123'
class MyThread(Thread):
def run(self):
global request
request = 'abc'
print('子线程',request) #子线程 abc
mythread = MyThread()
mythread.start()
mythread.join()
print('主线程',request) #主线程 abc
如果用local对象,在每个线程中都是隔离的
from threading import Thread
from werkzeug.local import Local
locals = Local()
locals.request = '123'
class MyThread(Thread):
def run(self):
locals.request = 'abc'
print('子线程',locals.request) #子线程 abc
mythread = MyThread()
mythread.start()
mythread.join()
print('主线程',locals.request) #主线程 123
app上下文和request上下文
应用上下文和请求上下文都是存放在一个‘LocalStack'的栈中,和应用app相关的操作就必须要用到应用上下文,比如通过current_app获取当前的这个app的名字。和请求相关的操作就必须用到请求上下文,比如使用url_for反转视图函数。
在视图函数中,不用担心上下文的问题,因为视图函数要执行,name肯定是通过访问url的方式执行的,name这种情况下,Flask底层就已经自动的帮我们把请求上年文和应用上下文都推入到了相应的栈中。如果想要在视图函数外面执行相关的操作,name就必须要手动推入相关的上下文手动推入请求上下文:推入请求上下文到栈中,会首先判断有没有应用上下文,如果没有那么就会先推入应用上下文到栈中,然后再推入请求上下文到栈中。
app上下文
from flask import Flask,current_app
app = Flask(__name__)
#如果在视图函数外部访问,则必须手动推入一个app上下文到app上下文栈中
#第一种方法
# app_context = app.app_context()
# app_context.push()
# print(current_app.name)
#第二种方法
with app.app_context():
print(current_app.name) #context_demo
@app.route('/')
def index():
# 在视图函数内部可以直接访问current_app.name
print(current_app.name) #context_demo
return 'Hello World!'
if __name__ == '__main__':
app.run(debug=True)
request请求上下文
from flask import Flask,current_app,url_for
app = Flask(__name__)
#应用上下文
#如果在视图函数外部访问,则必须手动推入一个app上下文到app上下文栈中
with app.app_context():
print(current_app.name) #context_demo
@app.route('/')
def index():
# 在视图函数内部可以直接访问current_app.name
print(current_app.name) #context_demo
return 'Hello World!'
@app.route('/list/')
def my_list():
return 'my_list'
# 请求上下文
with app.test_request_context():
# 手动推入一个请求上下文到请求上下文栈中
# 如果当前应用上下文栈中没有应用上下文
# 那么会首先推入一个应用上下文到栈中
print(url_for('my_list'))
if __name__ == '__main__':
app.run(debug=True)
为什么上下文需要放在栈中?
1.应用上下文:
Flask底层是基于werkzeug,werkzeug是可以包含多个app的,所以这时候用一个栈来保存,如果你在使用app1,那么app1应该是要在栈的顶部,如果用完了app1那么app应该从栈中删除,方便其他代码使用下面的app。
2.应用上下文:
如果在写测试代码,或者离线脚本的时候,我们有时候可能需要创建多个请求上下文,这时候就需要存放到一个栈中了。使用哪个请求上下文的时候,就把对应的请求上下文放到栈的顶部,用完了就要把这个请求上下文从栈中移除掉。
线程隔离的g对象
g对象是在整个Flask应用运行期间都是可以使用的,并且它也是跟request一样是线程隔离的。这个对象是专门用来存储开发者自定义的一些数据,方便在整个Flask程序中都可以使用。一般使用就是,将一些经常会用到的数据绑定到上面,以后就直接从g上面取就可以了,而不是通过传参的形式,这样更加方便。

