背景:
接口访问后返回的cookies,需要保存在文本中,然后其他接口请求时直接去读取文本中的内容。问题在于转储cookies时出现同一字段内容丢失的情况;
cookies内容查看(CSDN为例):
Request Cookies:
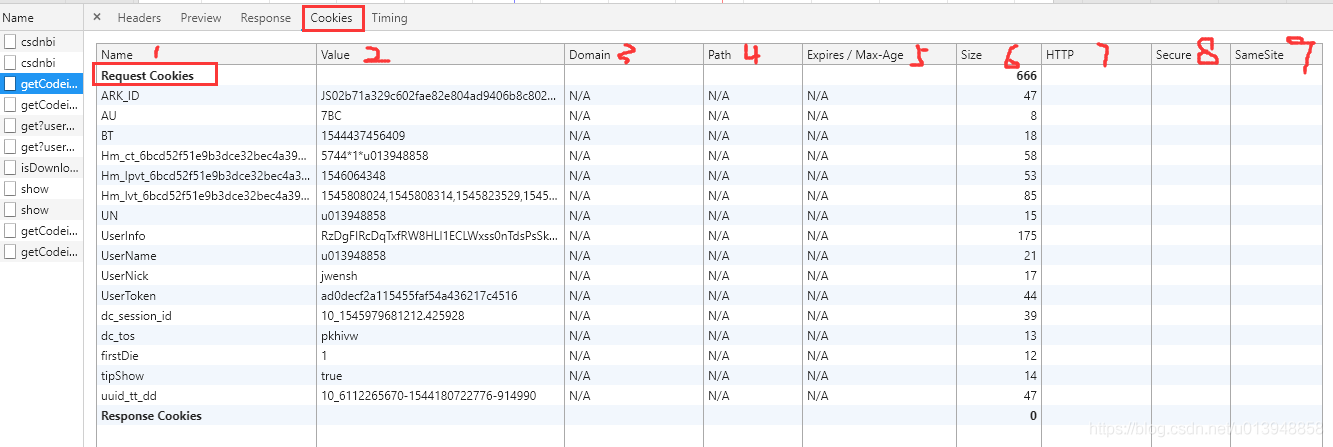
Response Cookies
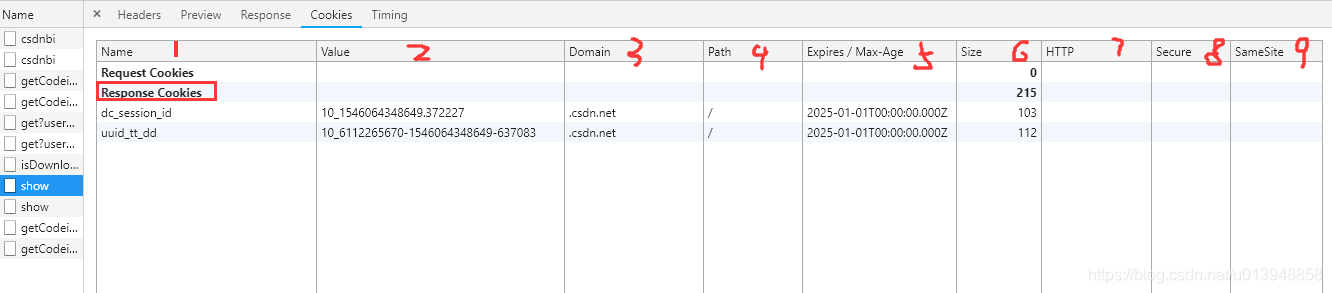
同上两套图可以看出:Cookie的内容很丰富,有很多属性,有name、value、domain、path等特征。不同的域不同的路径下可以存在同样名字的cookie。也就是说同一个请求或返回不会存在所有字段都一样的内容的cookie。当让我们一般的请求里,只会设置cookie的name和value,所以在这种意识下处理cookie会导致一些数据丢失。
cookies的字段说明:
| 属性 | 描述 |
|---|---|
| name | Cookie的名称,Cookie一旦创建,名称便不可更改 |
| value | Cookie的值。如果值为Unicode字符,需要为字符编码。如果值为二进制数据,则需要使用BASE64编码 |
| expires/maxAge | Cookie失效的时间,单位秒。如果为正数,则该Cookie在maxAge秒之后失效。如果为负数,该Cookie为临时Cookie,关闭浏览器即失效,浏览器也不会以任何形式保存该Cookie。如果为0,表示删除该Cookie。默认为-1。 |
| secure | 该Cookie是否仅被使用安全协议传输。安全协议。安全协议有HTTPS,SSL等,在网络上传输数据之前先将数据加密。默认为false。 |
| path | Cookie的使用路径。如果设置为“/sessionWeb/”,则只有contextPath为“/sessionWeb”的程序可以访问该Cookie。如果设置为“/”,则本域名下contextPath都可以访问该Cookie。注意最后一个字符必须为“/”。 |
| domain | 可以访问该Cookie的域名。如果设置为“.google.com”,则所有以“google.com”结尾的域名都可以访问该Cookie。注意第一个字符必须为“.”。 |
| comment | 该Cookie的用处说明,浏览器显示Cookie信息的时候显示该说明。 |
| version | Cookie使用的版本号。0表示遵循Netscape的Cookie规范,1表示遵循W3C的RFC 2109规范 |
由上面的表我们大致的了解下字段的含义啊,可能一些字段没有点出来,但是够用了,上图中有http,应该是http-only。用不上也就暂时不管了。
应用:python+requests去处理接口--cookies(防止丢失)
# !/usr/bin/env python
# -*-coding:utf-8-*-
import requests,json
def renren_login():
url='http://'
data = {}
headers = {}
r = requests.post(url=url, headers=headers, data=data)
cookies_file=requests.utils.dict_from_cookiejar(r.cookies) # 将cookiejar转化为字典
json.dump(cookies_file,open('renren_cookies','w')) # 用json.dump写到文件中
return r.cookies
def up_files():
url=''
data = {}
headers = {}
files={'file':('1.jpg',open('C:\\1.jpg','rb'),'image/jpeg')}
cookies=json.load(open('renren_cookies','r')) # 读取文件中的cookies
# 此处有个问题:"dict转为cookiesjar时候,cookie中有个字段是重复的,因此字典中就少了一个key值"
dict_cookiesjar=requests.utils.cookiejar_from_dict(cookies,cookiejar=None,overwrite=True)
r = requests.post(url=url,headers=headers,data=data,cookies=cookies,files=files)
print(r.text)
up_files()
分析一下:dict_from_cookiejar方法去转存cookie的时候,他只保留了name和value,其他的字段没有考虑在内,所以原来同名的cookie会被去重,那么我们想要保存cookie到文件里怎么办?那么就重新设计一种方式去存,因为我们现在知道cookie都有哪些字段了,我们需要什么,我们就存什么,上示例:
# !/usr/bin/env python
# -*-coding:utf-8-*-
import requests,json
from requests.cookies import RequestsCookieJar,create_cookie
# 方法有很多,可以选择把requests.utils.dict_from_cookiejar方法重写一下 改成list,
# 要点是要保证数据的唯一性,list可重复,还有就是每一位都是一个tuple,
def list_from_cookiejar(cj):
cookie_list = list()
for cookie in cj:
# 可以根据需求去保存cookie的特征值
cookie_list.append((cookie.name, cookie.value, cookie.path))
return cookie_list
# 去加载文件中list,核心代码是create_cookie:回给人多cookie对象的参数去实例化
def reload_cookie_from_file(cookiejar=None, overwrite=True):
if cookiejar is None:
cookiejar = RequestsCookieJar()
names_from_jar = [cookie.name for cookie in cookiejar]
with open("cookie_file", "r+") as cf:
for c_ in cf:
c_ = str(c_).strip().split("=")
if overwrite or (c_[0] not in names_from_jar):
# 根据保存的重新读取 并实例化为cookie
cookiejar.set_cookie(create_cookie(c_[0], c_[1], path=c_[2]))
return cookiejar
# 把接口获取的cookies转化为list,保存到文件中
def renren_login_for_dump():
url=''
data = {}
headers = {}
r = requests.post(url=url, headers=headers, data=data)
cookies_file=list_from_cookiejar(r.cookies) #将cookiejar转化为二位数组
print cookies_file
with open("cookie_file", "w+") as cf:
for c in cookies_file:
cf.write(str(c[0]+"="+c[1]+"="+ c[2]) + "\n")
cf.flush()
# return r.cookies
# 直接调用方法就可以使用了,没必要使用json去dump和reload
def up_files_with_cookie():
url=''
data = {}
headers = {}
files={'file':('1.jpg',open('C:\\1.jpg','rb'),'image/jpeg')}
cookies=reload_cookie_from_file()
r = requests.post(url=url,headers=headers,data=data,cookies=cookies,files=files)
print(r.text)
# print reload_cookie_from_file()
up_files_with_cookie()
总结:
1.对操作的对象要有特征上的认识;
2.一些问题一般都在官方文档和源码里给出了,需要去探索和发现;

