大家好,我是何三,80后老猿,独立开发者
每次看到小红书上的爆款笔记,你是不是也在想:这些内容是怎么创作出来的?为什么别人的笔记总能获得高互动,而自己的却石沉大海?今天我要分享的这套自动化流程,或许能帮你打开新世界的大门。
想象一下,你只需要运行一个脚本,就能自动生成10条、100条甚至更多完整的小红书笔记——包含吸引人的标题、精心设计的文案、风格统一的配图,还有恰到好处的标签。这一切,只需要Python和DeepSeek的强强联合就能实现。
先来看一组生成好的图片和文案:
文案:
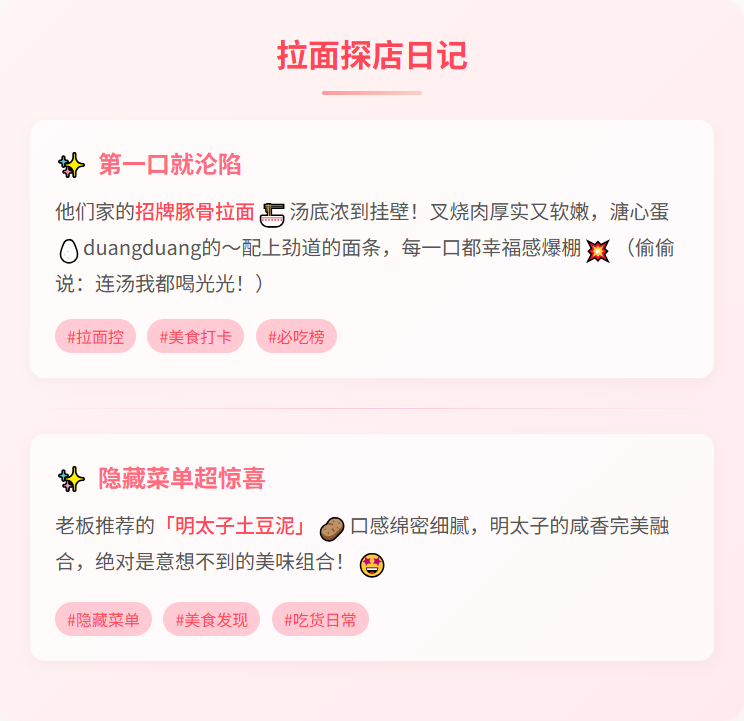
标题: 🍜这家店让我一周打卡三次!绝了✨
文案:
🍜这家店让我一周打卡三次!绝了✨
姐妹们!我真的要按头安利这家店!!😍 自从上周被闺蜜拉来尝鲜,我已经连续打卡三次了…(别问,问就是真爱!)
🌟 **第一口就沦陷**
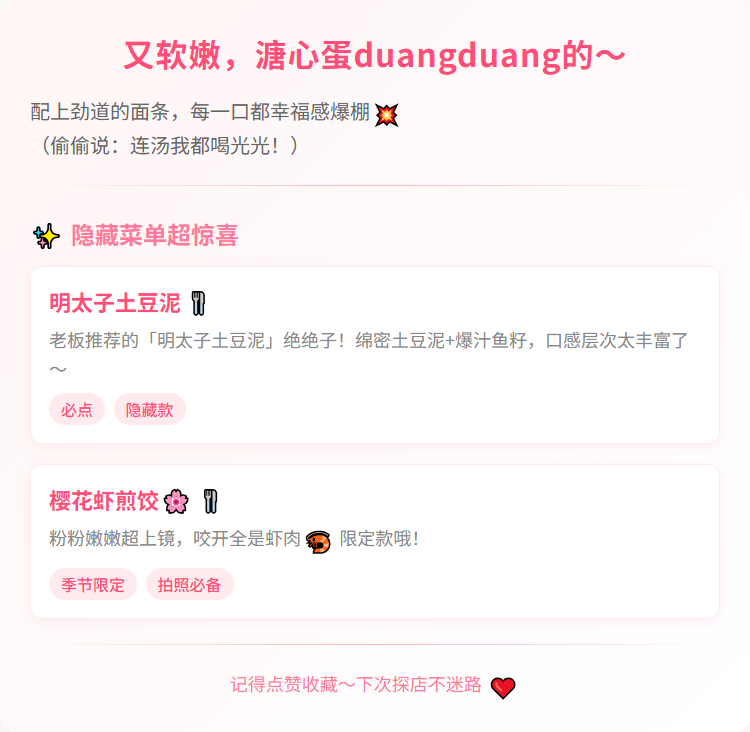
他们家的招牌豚骨拉面🍜汤底浓到挂壁!叉烧肉厚实又软嫩,溏心蛋duangduang的~配上劲道的面条,每一口都幸福感爆棚💥(偷偷说:连汤我都喝光光!)
🍗 **隐藏菜单超惊喜**
老板推荐的「明太子土豆泥」绝绝子!绵密土豆泥+爆汁鱼籽,口感层次太丰富了~还有限定款「樱花虾煎饺」🌸粉粉嫩嫩超上镜,咬开全是虾肉🦐
📸 **拍照打卡圣地**
日式原木风装修+暖黄灯光,随便一拍就是ins风大片!门口还有巨型招财猫可以合影🐱(建议穿浅色衣服更出片哦~)
💡 **小贴士**
▫️ 饭点要排队!建议错峰or提前取号
▫️ 人均50+,性价比超高
▫️ 隐藏菜单要主动问店员~
真的求你们快去!!吃完你会回来感谢我的🤣👇
#美食探店 #吃货日常 #拉面控 #日式料理 #周末去哪儿
配图:
output/note_0/img_0.png
output/note_0/img_1.png
为什么选择自动化内容生成?
在开始之前,我们先聊聊痛点。手动创作内容最大的问题是什么?是时间成本。构思一个标题可能要半小时,写文案又得半小时,找配图再花半小时...而当我们把这些流程自动化后,生成一条完整笔记的时间可以缩短到分钟级别。
更重要的是,自动化系统可以基于数据不断优化。你可以批量生成不同风格的笔记,测试哪种类型更受欢迎,然后调整生成策略。这种数据驱动的内容创作方式,是手动创作难以比拟的。
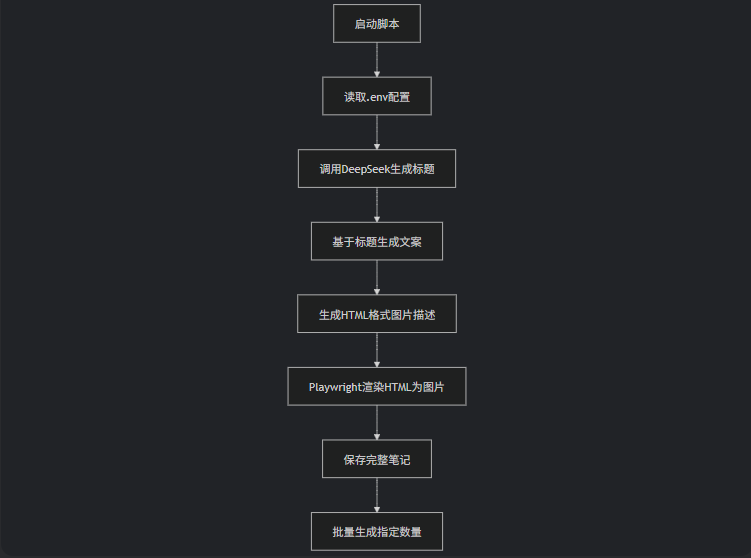
系统架构与核心组件
我们的系统主要由以下几个部分组成:
- DeepSeek API - 负责生成标题、文案和HTML格式的图片描述
- Playwright - 将HTML渲染为实际图片
- Python脚本 - 串联整个流程,处理配置和文件存储
整个流程像一条精心设计的流水线:从创意生成到视觉呈现,每个环节都紧密衔接。下面这张图展示了完整的工作流:
环境准备与配置
让我们从最基础的开始。首先创建一个.env文件来存放我们的配置参数:
DEEPSEEK_API_KEY=your_api_key_here
NOTES_COUNT=5
IMAGES_PER_NOTE=3
CONTENT_THEME=美食探店
STYLE=轻松活泼
TARGET_AUDIENCE=20-30岁女性
这些参数控制着内容生成的方向。比如CONTENT_THEME定义了笔记的主题领域,STYLE决定了文案的语气,而TARGET_AUDIENCE则确保内容针对特定人群优化。
安装必要的Python包:
pip install python-dotenv requests playwright beautifulsoup4
playwright install
核心代码实现
现在来到最激动人心的部分——代码实现。我会逐步解释每个关键模块,确保你能理解其中的逻辑。
首先,创建一个xiaohongshu_auto.py文件:
import os
import requests
from dotenv import load_dotenv
from bs4 import BeautifulSoup
from playwright.sync_api import sync_playwright
import time
import random
# 加载环境变量
load_dotenv()
class XiaohongshuAutoGenerator:
def __init__(self):
self.api_key = os.getenv("DEEPSEEK_API_KEY")
self.notes_count = int(os.getenv("NOTES_COUNT", 5))
self.images_per_note = int(os.getenv("IMAGES_PER_NOTE", 3))
self.content_theme = os.getenv("CONTENT_THEME", "生活方式")
self.style = os.getenv("STYLE", "亲切自然")
self.target_audience = os.getenv("TARGET_AUDIENCE", "18-35岁年轻女性")
# 确保输出目录存在
os.makedirs("output/notes", exist_ok=True)
os.makedirs("output/images", exist_ok=True)
def call_deepseek_api(self, prompt):
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
payload = {
"model": "deepseek-chat",
"messages": [
{
"role": "user",
"content": prompt
}
],
"temperature": 0.7
}
response = requests.post(
"https://api.deepseek.com/v1/chat/completions",
headers=headers,
json=payload
)
if response.status_code == 200:
return response.json()["choices"][0]["message"]["content"]
else:
raise Exception(f"API调用失败: {response.status_code}, {response.text}")
def generate_note_title(self):
prompt = f"""请为小红书生成一个关于{self.content_theme}的爆款标题,要求:
1. 包含emoji表情
2. 长度不超过20个字
3. 风格为{self.style}
4. 目标受众是{self.target_audience}
请直接返回标题内容,不需要其他说明。"""
return self.call_deepseek_api(prompt).strip('"')
def generate_note_content(self, title):
prompt = f"""根据以下标题为小红书生成一篇完整的笔记文案:
标题:{title}
要求:
1. 文案风格为{self.style}
2. 目标受众是{self.target_audience}
3. 包含适当的表情符号
4. 段落分明,有吸引力
5. 结尾添加3-5个相关话题标签
请直接返回文案内容,不需要其他说明。"""
return self.call_deepseek_api(prompt)
def generate_image_html(self, description):
prompt = f"""根据以下内容生成一个适合小红书配图的HTML代码:
描述:{description}
要求:
1. 使用div布局,宽度750px,高度任意
2. 背景色为浅粉色或浅黄色
3. 包含美观的文字排版
4. 添加一些装饰元素
5. 风格为{self.style}
只返回HTML代码,不需要其他说明。"""
return self.call_deepseek_api(prompt)
def render_html_to_image(self, html, filename):
with sync_playwright() as p:
browser = p.chromium.launch()
page = browser.new_page()
# 设置视口大小
page.set_viewport_size({"width": 800, "height": 1200})
# 加载HTML内容
page.set_content(html)
# 等待加载完成
time.sleep(1)
# 截图保存
page.screenshot(path=filename, full_page=True)
browser.close()
def generate_single_note(self, index):
# 生成标题
title = self.generate_note_title()
print(f"生成笔记 {index+1}: {title}")
# 生成文案内容
content = self.generate_note_content(title)
# 生成图片
image_filenames = []
for i in range(self.images_per_note):
# 从文案中提取一段作为图片描述
desc_start = random.randint(0, len(content)//2)
desc_end = desc_start + random.randint(50, 150)
description = content[desc_start:desc_end]
# 生成HTML并渲染为图片
html = self.generate_image_html(description)
image_filename = f"output/images/note_{index}_img_{i}.png"
self.render_html_to_image(html, image_filename)
image_filenames.append(image_filename)
# 保存完整笔记
note_filename = f"output/notes/note_{index}.txt"
with open(note_filename, "w", encoding="utf-8") as f:
f.write(f"标题: {title}\n\n")
f.write(f"文案:\n{content}\n\n")
f.write("配图:\n")
for img in image_filenames:
f.write(f"{img}\n")
return note_filename
def generate_all_notes(self):
for i in range(self.notes_count):
try:
self.generate_single_note(i)
print(f"成功生成笔记 {i+1}/{self.notes_count}")
except Exception as e:
print(f"生成笔记 {i+1} 时出错: {str(e)}")
if __name__ == "__main__":
generator = XiaohongshuAutoGenerator()
generator.generate_all_notes()
print("所有笔记生成完成!")
代码深度解析
让我们仔细看看这个脚本是如何工作的:
-
初始化阶段:从.env文件加载所有配置,创建必要的输出目录。
-
DeepSeek API交互:
call_deepseek_api方法处理与DeepSeek API的所有通信,包括设置请求头和解析响应。 -
内容生成三部曲:
generate_note_title: 生成吸引眼球的标题generate_note_content: 基于标题扩展成完整文案-
generate_image_html: 将文案片段转化为美观的HTML设计 -
图片渲染:
render_html_to_image使用Playwright将HTML代码实际渲染为PNG图片。 -
批量生成:
generate_all_notes方法控制整个流程,按指定数量生成完整笔记。
实际应用与优化建议
运行这个脚本后,你会在output目录下找到生成的笔记和图片。但真正的威力在于如何优化这个系统:
-
内容质量提升:通过调整提示词(prompt)来获得更好的输出。比如在生成标题时,可以要求API"列出5个标题供选择"。
-
A/B测试:批量生成不同风格的笔记,实际发布到小红书测试哪种类型表现最好。
-
个性化配置:根据你的细分领域调整.env参数。比如美妆类内容可以使用更精致的HTML模板。
-
性能优化:如果需要生成大量内容,可以考虑使用异步请求来加速API调用。
常见问题与解决方案
在实际使用中,你可能会遇到:
-
API限制问题:DeepSeek API可能有速率限制,解决方法是在调用间添加短暂延迟。
-
HTML渲染不一致:不同设备上Playwright的渲染结果可能略有不同,建议固定浏览器版本。
-
内容重复性:如果发现生成内容过于相似,可以增加temperature参数值来提升多样性。
-
图片风格单一:通过修改HTML生成提示词,引入更多样化的设计模板。
从自动化到智能化
这个基础版本已经能帮你节省大量时间,但还有更多可能性等待探索:
- 添加情感分析模块,自动调整文案语气
- 集成小红书API,实现自动发布
- 加入数据分析组件,跟踪笔记表现并反馈优化生成策略
- 开发可视化界面,让非技术用户也能轻松使用
记住,自动化不是要完全取代人工创作,而是将你从重复劳动中解放出来,让你能专注于更有创造性的工作。这套系统生成的笔记,应该作为初稿,再由你进行最后的润色和调整。
最后
在这个内容为王的时代,拥有高效的内容生产工具就等于掌握了流量密码。通过Python和DeepSeek的结合,我们不仅实现了内容批量化生产,更重要的是建立了一个可迭代、可优化的创作系统。
现在,你已经拥有了一个强大的内容生成引擎。接下来要做的,就是运行它,观察结果,然后不断调整优化。谁知道呢,或许下一个小红书爆款作者,就是你!
完整代码已上传知识星球


