大家好,我是何三,80后老猿,独立开发者
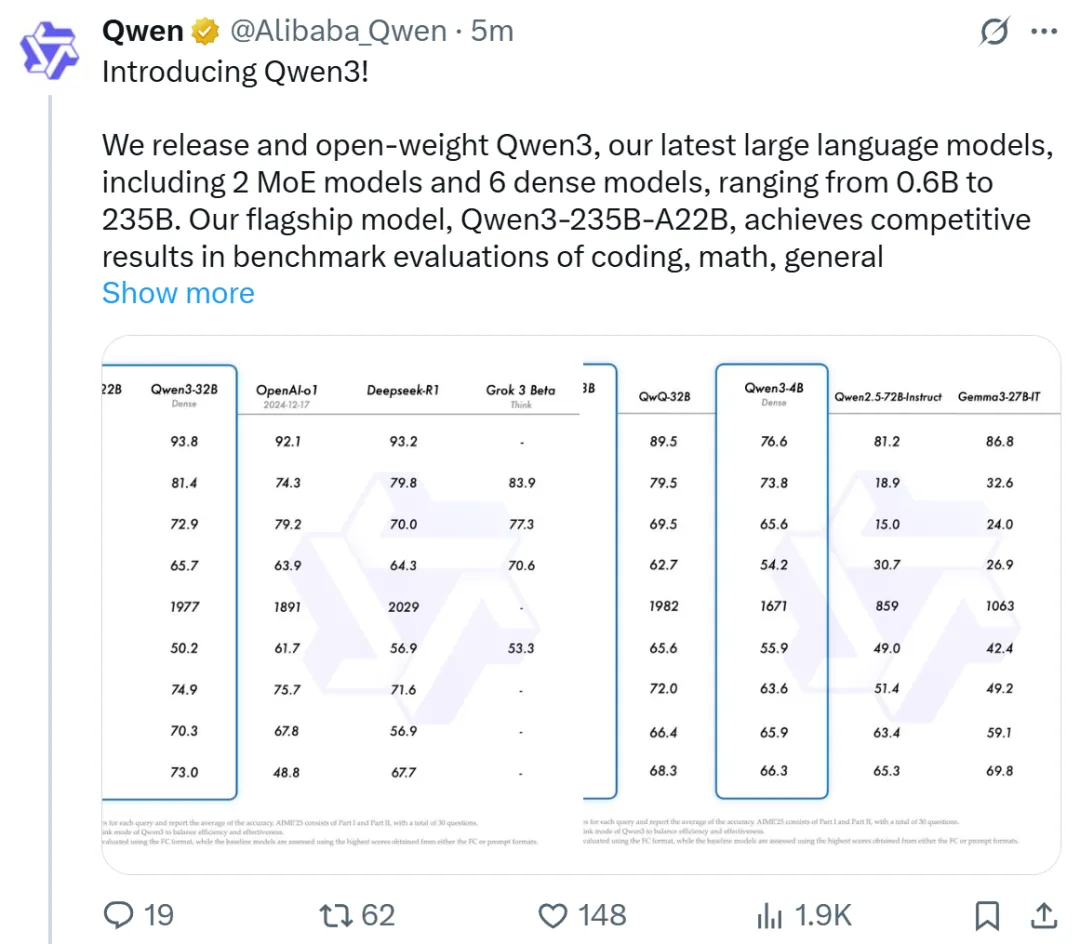
昨晚整个AI圈被阿里通义千问的Qwen3刷屏了!这波操作直接把OpenAI的o1和深度求索的DeepSeek-R1按在地上摩擦——全球开源模型榜单被中国人承包了!
一、模型全家桶震撼来袭
阿里这次直接甩出八款模型组成的"灭霸手套":
- 双料MoE大佬:235B参数的"巨无霸"和30B参数的"小钢炮"
- 六大密集模型:从32B到0.6B的"变形金刚战队"
最离谱的是那个0.6B的小老弟,用手机就能跑得飞起!用普通的电脑分分钟给你写出一份《论程序员如何优雅摸鱼》的万字长文...
二、性能吊打前代旗舰
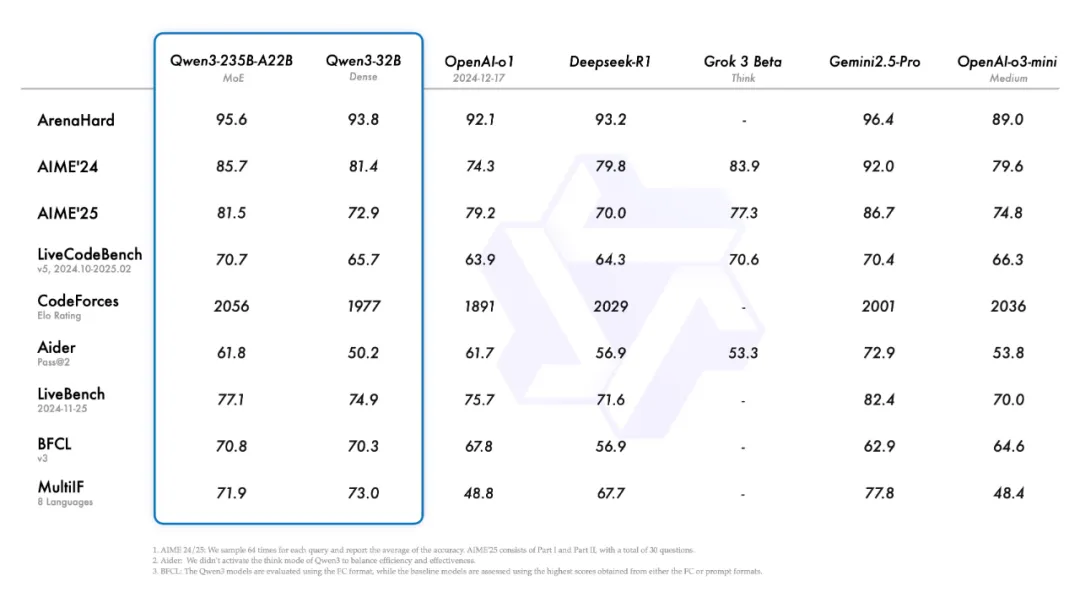
- 代码能力:让Qwen3-4B和自家72B的老前辈掰手腕,结果4B居然把72B按在地上摩擦
- 数学推理:235B版本直接解出我出的《九章算术》应用题,还附赠三种解题思路
- 部署成本:四张显卡就能跑满血版,显存占用只要同行三分之一(矿老板狂喜)
三、三大黑科技亮瞎眼
- 双模切换:
- 深度思考模式:像老教授一样推演微积分
-
极速响应模式:比电梯里按关门键还快
-
119语种自由切换:
连温州话和粤语都能听懂(测试时它居然用潮汕话给我讲了个冷笑话) -
Agent能力开挂:
实测用Qwen3自动写爬虫抓取自家模型下载量,结果自动生成了数据可视化大屏——这波我怀疑阿里在套娃!
四、开发者狂喜大礼包
- HuggingFace 地址:https://huggingface.co/collections/Qwen/qwen3-67dd247413f0e2e4f653967f
- Modelscope 地址:https://modelscope.cn/collections/Qwen3-9743180bdc6b48
- GitHub 地址:https://github.com/QwenLM/Qwen3
- 博客地址:https://qwenlm.github.io/blog/qwen3/
- 试用地址:https://chat.qwen.ai/
五、中国开源力量崛起
从预训练的36万亿token数据量,到超越Llama的10万+衍生模型,阿里这波直接把中国开源生态送上王者宝座。更骚的是训练时用自家前代模型合成数据——这波我训练我自己?!

程序员朋友们还在等什么?赶紧git clone走起!


