爬虫第一步:目标站点分析
1.Chrome
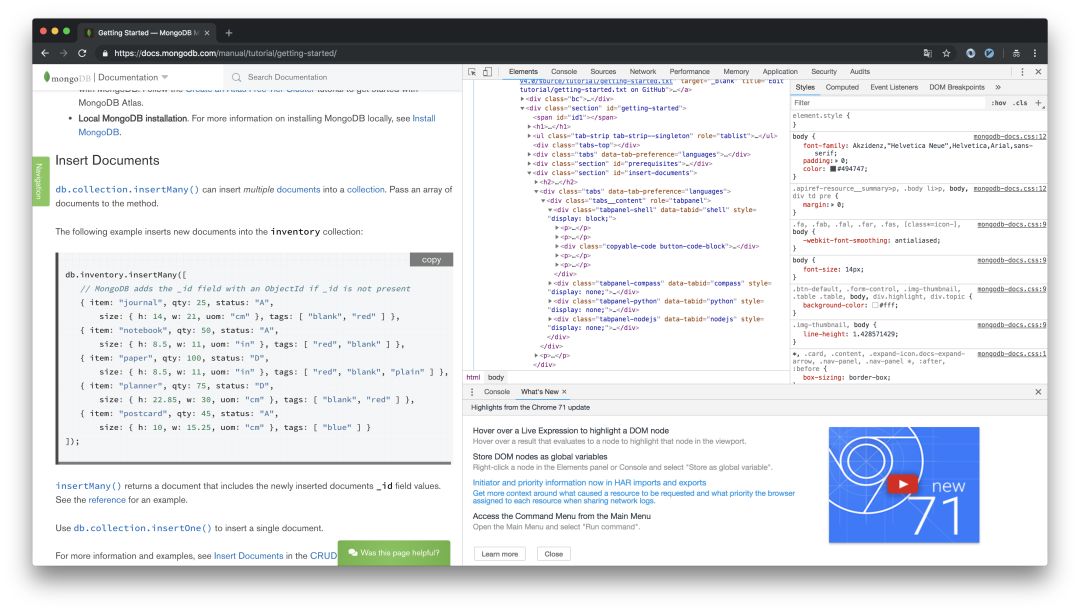
Chrome属于爬虫的基础工具,一般我们用它做初始的爬取分析,页面逻辑跳转、简单的js调试、网络请求的步骤等。我们初期的大部分工作都在它上面完成,打个不恰当的比喻,不用Chrome,我们就要从智能时代倒退到马车时代
同类工具: Firefox、Safari、Opera
2.Charles

Charles与Chrome对应,只不过它是用来做App端的网络分析,相较于网页端,App端的网络分析较为简单,重点放在分析各个网络请求的参数。当然,如果对方在服务端做了参数加密,那就涉及逆向工程方面的知识,那一块又是一大箩筐的工具,这里暂且不谈
同类工具:Fiddler、Wireshark、Anyproxy
爬虫第二步:分析站点的反爬虫
3.cUrl

维基百科这样介绍它
cURL是一个利用URL语法在命令行下工作的文件传输工具,1997年首次发行。它支持文件上传和下载,所以是综合传输工具,但按传统,习惯称cURL为下载工具。cURL还包含了用于程序开发的libcurl。
在做爬虫分析时,我们经常要模拟一下其中的请求,这个时候如果去写一段代码,未免太小题大做了,直接通过Chrome拷贝一个cURL,在命令行中跑一下看看结果即可,步骤如下


4.Postman


当然,大部分网站不是你拷贝一下cURL链接,改改其中参数就可以拿到数据的,接下来我们做更深层次的分析,就需要用到Postman“大杀器”了。为什么是“大杀器”呢?因为它着实强大。配合cURL,我们可以将请求的内容直接移植过来,然后对其中的请求进行改造,勾选即可选择我们想要的内容参数,非常优雅
5.Online JavaScript Beautifier

用了以上的工具,你基本可以解决大部分网站了,算是一个合格的初级爬虫工程师了。这个时候,我们想要进阶就需要面对更复杂的网站爬虫了,这个阶段,你不仅要会后端的知识,还需要了解一些前端的知识,因为很多网站的反爬措施是放在前端的。你需要提取对方站点的js信息,并需要理解和逆向回去,原生的js代码一般不易于阅读,这时,就要它来帮你格式化吧
6.EditThisCookie

爬虫和反爬虫就是一场没有硝烟的拉锯战,你永远不知道对方会给你埋哪些坑,比如对Cookies动手脚。这个时候你就需要它来辅助你分析,通过Chrome安装EditThisCookie插件后,我们可以通过点击右上角小图标,再对Cookies里的信息进行增删改查操作,大大提高对Cookies信息的模拟
爬虫第三步:设计爬虫架构
7.Sketch

当我们已经确定能爬取之后,我们不应该着急动手写爬虫。而是应该着手设计爬虫的结构。按照业务的需求,我们可以做一下简单的爬取分析,这有助于我们之后开发的效率,所谓磨刀不误砍柴工就是这个道理。比如可以考虑下,是搜索爬取还是遍历爬取?采用BFS还是DFS?并发的请求数大概多少?考虑一下这些问题后,我们可以通过Sketch来画一下简单的架构图
同类工具:Illustrator、 Photoshop
爬虫第四步:正式爬虫开发之旅
终于要进行开发了,经过上面的这些步骤,我们到这一步,已经是万事俱备只欠东风了。这个时候,我们仅仅只需要做code和数据提取即可
8.XPath Helper

在提取网页数据时,我们一般需要使用xpath语法进行页面数据信息提取,一般地,但我们只能写完语法,发送请求给对方网页,然后打印出来,才知道我们提取的数据是否正确,这样一方面会发起很多不必要的请求,另外一方面,也浪费了我们的时间。这个就可以用到XPath Helper了,通过Chrome安装插件后,我们只需要点击它在对应的xpath中写入语法,然后便可以很直观地在右边看到我们的结果,效率up+10086
9.JSONView

我们有时候提取的数据是Json格式的,因为它简单易用,越来越多的网站倾向于用Json格式进行数据传输。这个时候,我们安装这个插件后,就可以很方便的来查看Json数据啦
10.JSON Editor Online

JSONView 是直接在网页端返回的数据结果是Json,但多数时候我们请求的结果,都是前端渲染后的HTML网页数据,我们发起请求后得到的json数据,在终端(即terminal)中无法很好的展现怎么办?借助JSON Editor Online就可以帮你很好的格式化数据啦,一秒格式化,并且实现了贴心得折叠Json数据功能
既然看到这里,相信你们一定是真爱粉啦,送你们一个彩蛋工具。
ScreenFloat

它能来干嘛?见名思意,就是一个屏幕悬浮工具,然而我最近才发现它特别重要,尤其我们需要分析参数时,经常需要在几个界面来回切换,这个时候有一些参数,我们需要比较他们的差异,这个时候,你就可以通过它先悬浮着,不用在几个界面中来切换,非常方便。

