
前戏
元素的定位是自动化测试的核心,要想操作一个元素,首先应该识别这个元素。Webdriver 提供了一系列的元素定位方法,常用的有 id,name,class name,link text,partial link,tag name,xpath,css
讲定位之前先要了解说一下怎么定位,我们打开百度的首页,按F12,打开开发者工具,大概就是这个样子,点击Element,这里就是前端写的HTML代码,你在页面上所看到的页面就是通过HTML语言和CSS等前端语言展示在浏览器中的
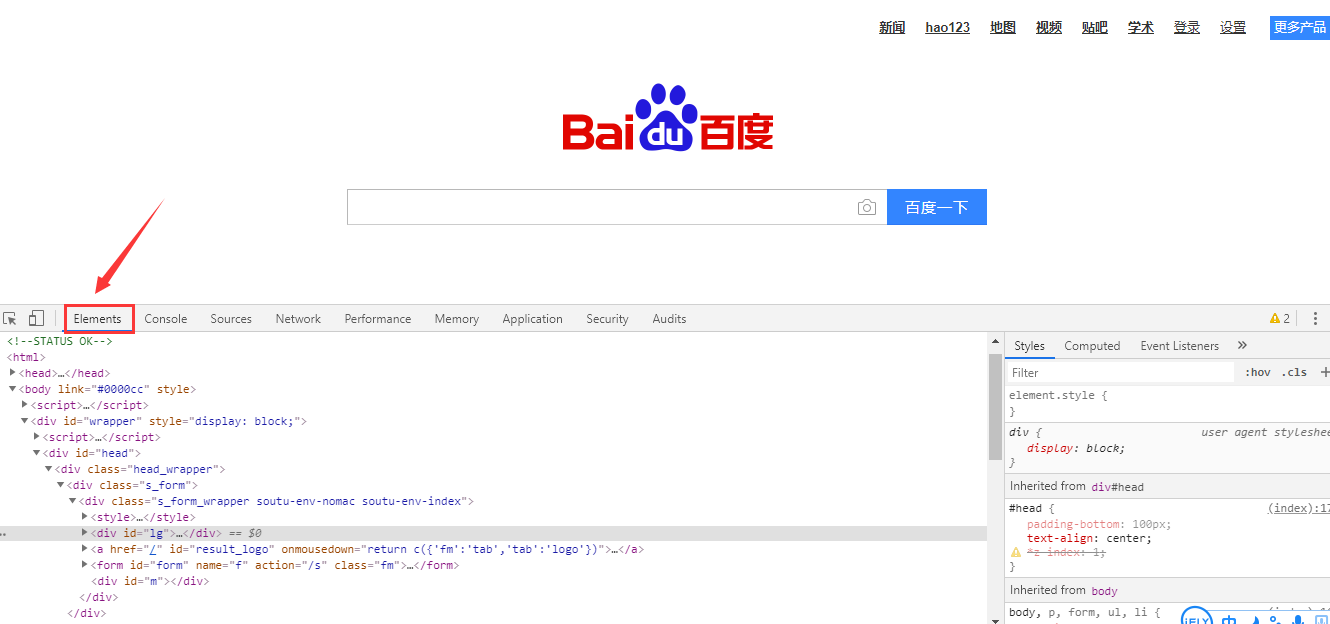
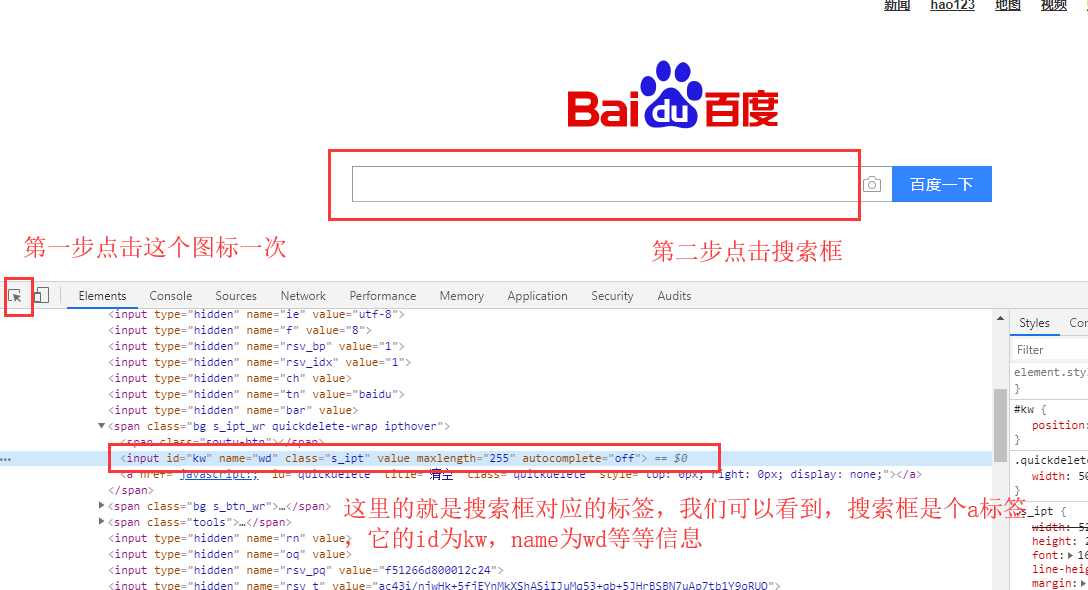
其实所有的定位,底层 都是通过css来定位的,以下是它的源代码
def find_element(self, by=By.ID, value=None):
"""
'Private' method used by the find_element_by_* methods.
:Usage:
Use the corresponding find_element_by_* instead of this.
:rtype: WebElement
"""
if self.w3c:
if by == By.ID:
by = By.CSS_SELECTOR
value = '[id="%s"]' % value
elif by == By.TAG_NAME:
by = By.CSS_SELECTOR
elif by == By.CLASS_NAME:
by = By.CSS_SELECTOR
value = ".%s" % value
elif by == By.NAME:
by = By.CSS_SELECTOR
value = '[name="%s"]' % value
return self.execute(Command.FIND_ELEMENT, {
'using': by,
'value': value})['value']
id定位
小需求:
打开百度首页,在搜索框里输入 selenium,python 等关键词,然后
点击搜索按钮,查看搜索页面
from selenium import webdriver
from time import sleep
drive = webdriver.Chrome()
drive.get('http://www.baidu.com')
sleep(3)
drive.find_element_by_id("kw").send_keys("selenium python") # 通过 id 定位到搜索框,发送值 selenium python,find_element_by_id 查找元素通过 id
sleep(3)
drive.find_element_by_id("su").click() # 通过 id 定位到搜索按钮,点击
sleep(3)
drive.quit()
这样就通过id定位到搜索框,通过send_keys给搜索框里传了selenium python关键字,然后定位到百度一下的按钮,click()点击
name定位
from selenium import webdriver
from time import sleep
drive = webdriver.Chrome()
drive.get('http://www.baidu.com')
sleep(3)
drive.find_element_by_name("wd").send_keys("英语") # 通过 name定位到搜索框,发送值英语,
sleep(3)
drive.find_element_by_id("su").click() # 通过 id 定位到搜索按钮,点击
sleep(3)
drive.quit()
tag_name定位
tag_name就是通过标签名定位
from selenium import webdriver
from time import sleep
drive = webdriver.Chrome()
drive.get('http://www.imooc.com')
drive.find_element_by_tag_name('input').send_keys('python') # 定位标签名为 input 的第一个元素
drive.find_elements_by_tag_name('input')[0].send_keys('python') # 定位标签名为 input 的元素,返回第一个
sleep(3)
drive.quit()
一般不通过标签名定位,因为他是从上到下依次取的
class_name
通过class属性值定位
from selenium import webdriver
from time import sleep
drive = webdriver.Chrome()
drive.get('http://www.baidu.com')
drive.find_element_by_class_name('s_ipt').send_keys('selenium')
drive.find_element_by_id('su').click()
sleep(3)
drive.quit()
通过超链接定位 link_text
selenium提供了两种超链接定位方式,第一种是链接文字(全部),第二种也是链接文字(部分文字)
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get('http://www.imooc.com')
driver.maximize_window()
driver.find_element_by_link_text('免费课程').click()
sleep(3)
driver.find_element_by_partial_link_text('后端').click() # 通过部分文字定位
driver.quit()
CSS定位
Selenium 推荐使用 css 定位,而不是 xpath 来定位元素,原因是 css 定
位比 xpath 定位速度快,语法也更加简洁
Css 常用方法定位
(1) find_element_by_css_selector()
(2) #id id 选择器根据 id 属性来定位元素
(3) .class class 选择器,根据 class 属性值来定位元素
(4) [attribute=’value’] 根据属性来定位元素
(5) element>element 根据元素层级来定位 父元素>子元素
来具体看两个例子
例子一:
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
driver.find_element_by_css_selector("#kw").send_keys('python') # 通过 id=kw 定位到
driver.find_element_by_css_selector('.s_ipt').send_keys('selenium') # 通过 class =s_ipt 定位
driver.find_element_by_css_selector("[autocomplete='off']").send_keys('python') # 通过属性 autocomplete=off 定位
driver.find_element_by_css_selector('#su').click()
sleep(2)
driver.quit()
例子二:
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
driver.find_element_by_css_selector("[autocomplete='off']").send_keys('python') # 通过属性 autocomplete=off 定位
driver.find_element_by_css_selector('form#form>span>input').send_keys('6666')
# 通过层级定位到输入框,先定位到id=form 的上级标签 form 上,在定位到下级 span 上,最后定位到第一个 input 标签
driver.find_element_by_css_selector('#su').click()
sleep(2)
driver.quit()
不知道大家看懂上面的定位方式了没,官方说比较简洁,但是我没觉得哪里简洁,我只是在学的时候用过CSS定位,在实际的工作中从来没有用过CSS定位。也许我比较菜吧,啊哈哈哈哈哈
当然。css还有其他的用法
目的:查找第一个div标签下的“查询”按钮
html>body>div>input[value='查询']
python定位语句
driver.find_element_by_css_selector("html>body>div>input[value='查询']")
通过">"符号分割,区别于XPath路径中的正斜杠(/),并且也不在使用@符号选择属性
2.使用相对路径定位
目的:查找第一个div标签下的“查询”按钮
input[value='查询']
python定位语句
driver.find_element_by_css_selector("input[value='查询']")
3.使用class名称定位元素
目的:查找第一个div标签下的input输入框
driver.find_element_by_css_selector(".spread")
4.使用id属性值定位
目的:查找第一个div标签下ID属性值为"div1input"的input页面元素
driver.find_element_by_css_selector("#div1nput")
5.使用页面其他属性值定位
目的:查找第一个div标签下的第一张图片img
(1):img[alt="div1-img1"]
(2):img[alt="div1-img1"][href="http://www.sogou.com"]
python定位语句
driver.find_element_by_css_selector('img[alt="div1-img1"][href="http://www.sogou.com"]')
(1)和(2)在本例中是等价的,(2)是使用了多个属性定位
6.使用属性值的一部分内容定位元素(貌似只能定位超链接)
目的:在被测网页中,查找“搜狗搜索”的链接
表达式1:a[href^="http://www.so"]
表达式2:a[href$="gou.com"]
表达式3:a[href*="so"]
python定位语句
driver.find_element_by_css_selector('a[href^="http://www.so"]')
表达式1表示匹配链接地址开始包含"http://www.so"关键字的链接元素,^表示从字符串的开头匹配
表达式2表示匹配链接地址开始包含"gou.com"关键字的链接元素,$表示从字符串的结尾匹配
表达式3表示匹配链接地址开始包含"so"关键字的链接元素,*表示需要进行模糊匹配
匹配动态变化的属性值
7.使用页面元素进行子页面元素的查找
目的:在被测网页中,查找第一个div下的第一个input标签
表达式1:div#div1>input#div1input
表达式2:div input
python定位语句
driver.find_element_by_css_selector('div#div1>input#div1input')
表达式1中的div#div1,表示在被测网页上定位到ID属性为div1的div标签,“>”表示在已查找到的div元素的子页面中进行查找,input#div1input表示查找ID属性值为div1input的input标签
表达式2表示匹配所有属于div元素后代的input元素,父元素div和子元素input间必须用空格分隔
8.使用伪类定位元素
目的:在被测网页中,查找第一个div下的指定子页面元素
表达式1:div#div1 :first-child
表达式2:div#div1 :nth-child(2)
表达式3:div#div1 :last-child
表达式4:input:focus
表达式5:input:enabled
表达式6:input:checked
表达式7:input:not([id])
python定位语句:
driver.find_element_by_css_selector('input:not([id])')
前三个表达式要注意,在冒号(:)前一定要有一个空格,否则就会定位不到期望的页面元素
表达式1:表示查找ID属性值为div1的div页面元素下的第一个子元素,参考被测网页的HTML可以看到定位的页面元素是input元素,first-child表示查找某个页面元素下的第一个子页面元素
表达式2:表示查找ID属性值为div1的div页面元素下的第二个子元素,参考被测网页的HTML可以看到定位的页面元素是链接元素,nth-child(2)表示查找某个页面元素下的第二个子页面元素,nth-child(3)表示查找某个页面元素下的第三个子页面元素 ,以此类推
表达式3:表示查找ID属性值为div1的div页面元素下的最后一个子元素,参考被测网页的HTML可以看到定位的页面元素是按钮元素,last-child表示查找某个页面元素下的最后一个子页面元素
表达式4:表示查找当前获取焦点的input页面元素
表达式5:表示查找可操作的input页面元素
表达式6:表示查找处于勾选状态的checkbox页面元素
表达式7:表示查找所有无id属性的input页面元素
9.查找同级兄弟页面元素
目的:在被测网页中,查找第一个div下第一个input子页面元素的同级兄弟页面元素
表达式1:div#div1>input+a
表达式2:div#div1>input+a+img
表达式3:div#div1>input+*+img
表达式4:ul#recordlist>p~li
表达式1表示在ID属性值为div1的div页面元素下,查找input页面元素后面的同级且临近的链接元素a
表达式2表示在ID属性值为div1的div页面元素下,查找input页面元素和链接元素后面的同级且临近的图片元素img
表达式3表示在ID属性值为div1的div页面元素下,查找input页面元素和元素后面的同级且临近的图片元素img ,*表示任意类型的一个页面元素,只能表示一个页面元素,如果想用此种方法查找第一个div下的最后一个input元素,表达式写法为
div#div1>input+++input或div#div1>input+a+*+input或div#div1>input+a+img+input
表达式4表示子ID属性值为recordlist的ul页面元素下,查好p页面元素以后所有的li元素
10.多元素选择器
目的:在被测网页中,同时选择多个不同的页面元素
div#div,input,a
表示查找所有ID属性值为div1的div元素,所有的input元素,所有的a元素
下节来讲下xpath定位,也是我使用最多的定位,xpath定位功能十分的强大
python爬虫之selenium--获取HTML源码断言和URL地址
python爬虫之selenium--设置浏览器的位置和高度宽度
python爬虫之selenium--页面元素是否可见和可操作
python爬虫之selenium--高亮显示正在操作的元素
转自:https://www.cnblogs.com/zouzou-busy/p/11048711.html
专业python开发,在线接单,QQ(微信):466867714

