
前言
在我们之前写的自动化脚本中,不知道大家有没有发现,每次打开的都是一个新的浏览器(相当于新安装的)。但是有时候,我们想打开的是我们配置好的浏览器。我在之前的公司做web自动化的时候,由于我们的网站是n年前开发的(代码很low的那种),如果这时候你想上传图片,必须要在浏览器设置里给这个网站启用flash才能上传。如果每次打开的都是新浏览器的话,那根本就做不了自动化,所以这时候就要让selenium启动一个我们配置好的浏览器
Chrome浏览器
在Chrome浏览器的地址栏输入:chrome://version/,查看个人资料路径并复制路径
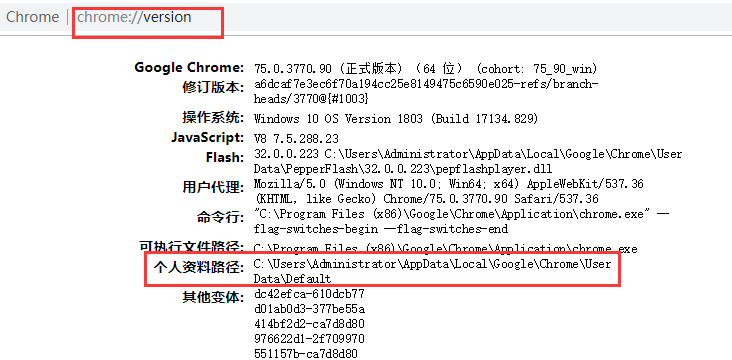
路径后面的Default不需要,不然还是打开一个新用户。
在执行脚本时,确保没有谷歌浏览器打开,不然会报selenium.common.exceptions.WebDriverException: Message: unknown error: Chrome failed to start: crashed
然后在实例化浏览器的时候写如下代码
from selenium import webdriver
# 个人资料路径
user_data_dir = r'--user-data-dir=C:\Users\Administrator\AppData\Local\Google\Chrome\User Data'
# 加载配置数据
option = webdriver.ChromeOptions()
option.add_argument(user_data_dir)
# 启动浏览器配置
driver = webdriver.Chrome(chrome_options=option, executable_path=r'D:\drivers\chromedriver.exe')
driver.get('https://www.baidu.com/')
Firefox浏览器
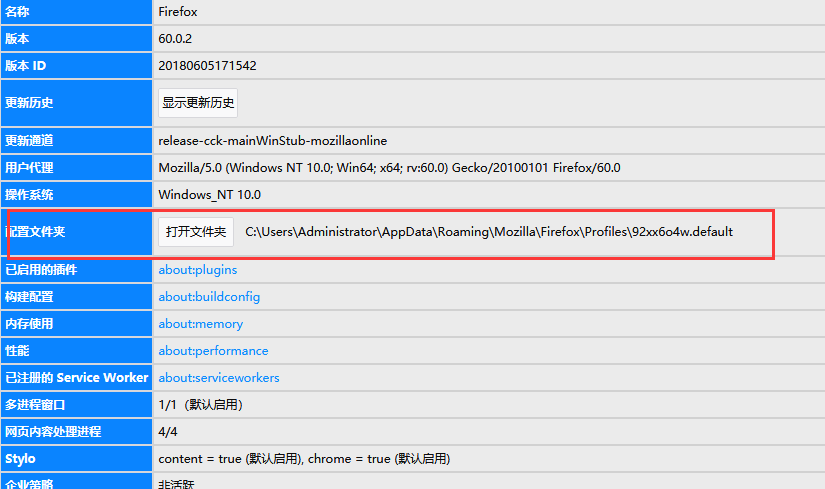
打开Firefox浏览器,进入右上角的帮助>故障排除信息,查看浏览器配置文件路径并复制此路径
from selenium import webdriver
# 配置文件路径
profile_path = r'C:\Users\Administrator\AppData\Roaming\Mozilla\Firefox\Profiles\92xx6o4w.default'
# 加载配置数据
profile = webdriver.FirefoxProfile(profile_path)
# 启动浏览器配置
driver = webdriver.Firefox(firefox_profile=profile, executable_path=r'D:\drivers\geckodriver.exe')
driver.get(r'http://www.baidu.com/')
driver.quit()
这样配置好之后,打开的浏览器都是我们配置好的浏览器,添加的标签等等都存在
python爬虫之selenium--获取HTML源码断言和URL地址
python爬虫之selenium--设置浏览器的位置和高度宽度
python爬虫之selenium--页面元素是否可见和可操作
python爬虫之selenium--高亮显示正在操作的元素
转自:https://www.cnblogs.com/zouzou-busy/p/11186302.html

