前言
最近有小伙伴提到如何抓取 table 表格上的数据,table表格的数据很简单,就是行和列。
可以按行抓取,也可以按列抓取。
获取table 某一列的数据

抓取第3列(项目名称)所有数据
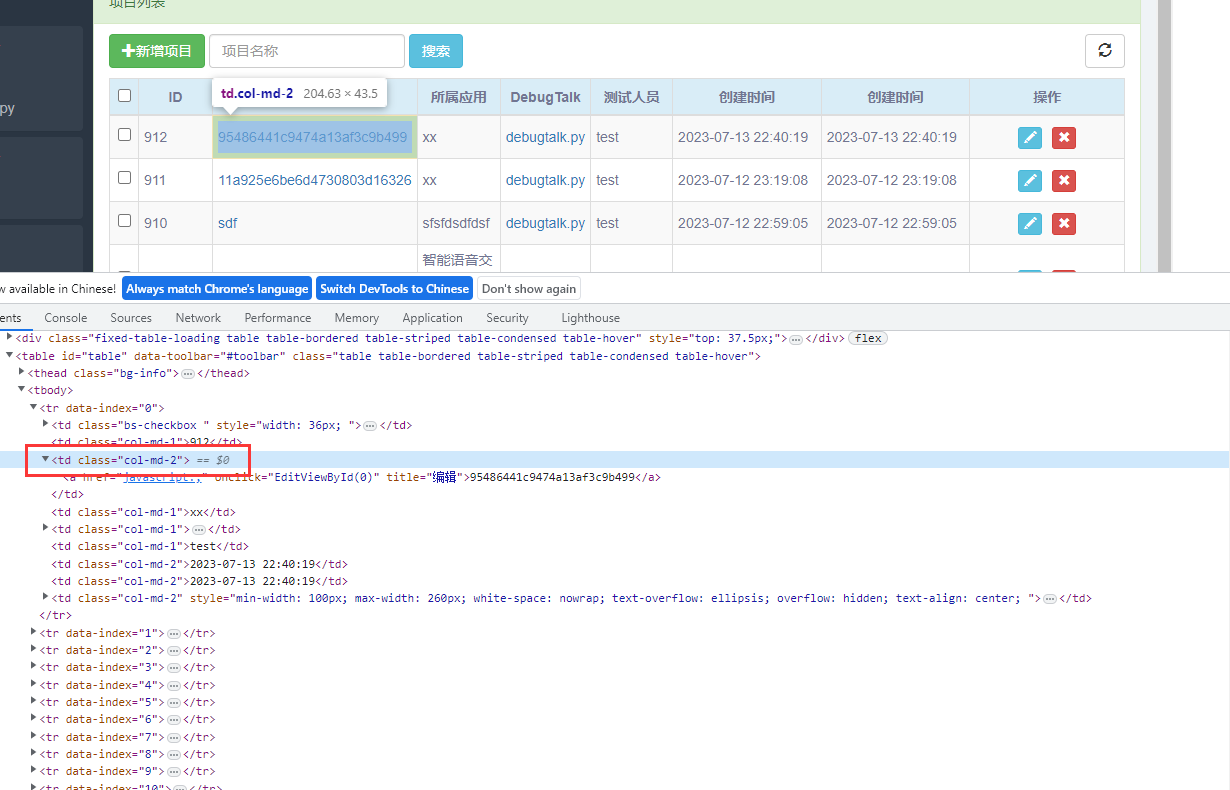
定位方式
$x('//table/tbody/tr/td[3]')
于是可以看到当前页面的第3列数据被全部定位到

接下来就可以根据定位的元素获取全部文本
# 作者:上海-悠悠 wx:283340479
# blog: https://www.cnblogs.com/yoyoketang/
# 抓取table表格数据
all_names = page.locator('//table/tbody/tr/td[3]')
all_text = [item.inner_text() for item in all_names.all()]
print(all_text)
打印结果
['95486441c9474a13af3c9b499', '11a925e6be6d4730803d16326', 'sdf', '智能语音交互平台1', '智能语音交互平台', 'af192f498ddc456b8ec7a8d9c', '9bbfa2e6cb65447082070c692', '1234', 'fa021c54fa92423fa9fd790c0', 'c401881da9244fe0bba884e86', '9a32fe638eb441beb74ba186f', '56d6bd63ec3449c898de56644', '326724fd85c744fdb7720af4b', '5ec8d9d8f8684245ac82e0f9f', 'c6a18619c7db4ac499c1ed5e3']
按行获取table表格全部数据

定位标题行
//table/thead/tr/th
定位他body数据行
//table/tbody/tr
按行抓取table表格数据,并且按标题以键值对方式存储数据
# 作者:上海-悠悠 wx:283340479
# blog: https://www.cnblogs.com/yoyoketang/
table_all_data = []
# 获取全部标题
all_titles = page.locator('//table/thead/tr/th')
titles_text = [item.inner_text() for item in all_titles.all()]
print(f'全部标题:{titles_text}')
all_tr = page.locator('//table/tbody/tr')
print(f"当前页面数量:{all_tr.count()}")
for i in range(all_tr.count()):
td_element = all_tr.all()[i].locator('td').all()
td_text = [item.inner_text() for item in td_element]
print(f"第 {i} 行数据:{td_text}")
table_all_data.append({key: value for key, value in zip(titles_text, td_text)})
# 当前页全部数据
print(table_all_data)
运行结果
全部标题:['', 'ID', '项目名称', '所属应用', 'DebugTalk', '测试人员', '创建时间', '创建时间', '操作']
当前页面数量:15
第 0 行数据:['', '912', '95486441c9474a13af3c9b499', 'xx', 'debugtalk.py', 'test', '2023-07-13 22:40:19', '2023-07-13 22:40:19', '']
第 1 行数据:['', '911', '11a925e6be6d4730803d16326', 'xx', 'debugtalk.py', 'test', '2023-07-12 23:19:08', '2023-07-12 23:19:08', '']
第 2 行数据:['', '910', 'sdf', 'sfsfdsdfdsf', 'debugtalk.py', 'test', '2023-07-12 22:59:05', '2023-07-12 22:59:05', '']
第 3 行数据:['', '909', '智能语音交互平台1', '智能语音交互平台web端', 'debugtalk.py', 'test', '2023-07-12 20:51:52', '2023-07-12 20:51:52', '']
第 4 行数据:['', '908', '智能语音交互平台', '智能语音交互平台web端', 'debugtalk.py', 'test', '2023-07-12 20:50:44', '2023-07-12 20:50:44', '']
第 5 行数据:['', '907', 'af192f498ddc456b8ec7a8d9c', 'xx', 'debugtalk.py', 'yoyo', '2023-07-11 11:46:33', '2023-07-11 11:46:33', '']
第 6 行数据:['', '906', '9bbfa2e6cb65447082070c692', 'xx', 'debugtalk.py', 'yoyo', '2023-07-11 11:45:21', '2023-07-11 11:45:21', '']
第 7 行数据:['', '905', '1234', '1234', 'debugtalk.py', 'yoyo', '2023-07-07 18:57:24', '2023-07-11 11:40:11', '']
第 8 行数据:['', '904', 'fa021c54fa92423fa9fd790c0', 'xx', 'debugtalk.py', 'yoyo', '2023-07-07 18:57:08', '2023-07-07 18:57:08', '']
第 9 行数据:['', '903', 'c401881da9244fe0bba884e86', 'xx', 'debugtalk.py', 'yoyo', '2023-07-07 18:54:35', '2023-07-07 18:54:35', '']
第 10 行数据:['', '902', '9a32fe638eb441beb74ba186f', 'xx', 'debugtalk.py', 'yoyo', '2023-07-07 18:52:11', '2023-07-07 18:52:11', '']
第 11 行数据:['', '901', '56d6bd63ec3449c898de56644', 'xx', 'debugtalk.py', 'yoyo', '2023-07-07 18:49:36', '2023-07-07 18:49:36', '']
第 12 行数据:['', '900', '326724fd85c744fdb7720af4b', 'xx', 'debugtalk.py', 'yoyo', '2023-07-07 18:48:54', '2023-07-07 18:48:54', '']
第 13 行数据:['', '899', '5ec8d9d8f8684245ac82e0f9f', 'xx', 'debugtalk.py', 'yoyo', '2023-07-07 18:47:27', '2023-07-07 18:47:27', '']
第 14 行数据:['', '898', 'c6a18619c7db4ac499c1ed5e3', 'xx', 'debugtalk.py', 'yoyo', '2023-07-07 18:46:07', '2023-07-07 18:46:07', '']
[{'': '', 'ID': '912', .....},
{'': '', 'ID': '911', '项目... # 数据省略
]
继续抓取后面的页面数据,只需点下一页按钮,做个循环

这样就可以批量抓取了。
通过接口抓取
如果table表格的数据是通过接口提供的,那抓取就更简单登录,直接拦截请求,得到接口返回的数据接口
# 作者:上海-悠悠 wx:283340479
# blog: https://www.cnblogs.com/yoyoketang/
# 前后端分离的项目,通过接口抓取
with page.expect_response('**/api/project**') as resp:
page.get_by_text('项目列表').click()
page.wait_for_timeout(3000)
response = resp.value
res = response.json()
print(res)
page.pause()
运行结果
{'total': 289, 'rows': [
{'id': 912, 'project_name': '95486441c9474a13af3c9b499', ....},
{'id': 911, .... # 数据省略
]
}
文章转自:https://www.cnblogs.com/yoyoketang/p/17574772.html

